개발공부 25,26일차 [웹개방종합반 3주차 2회완강 및 스터디]
2주차에 배운 javascript복습
fetch 기본골격
fetch("여기에 URL을 입력").then(res => res.json()).then(data => {
console.log(data)
})fetch("http://spartacodingclub.shop/web/api/movie")
.then((res) => res.json())
.then((data) => {
let movies = data['movies']
console.log(movies)
$('#cards-box').empty()
movies.forEach((movie) => {
let title = movie['title']
let comment = movie['comment']
let image = movie['image']
let desc = movie['desc']
let star = movie['star']
let star_image = '⭐️'.repeat(star)
let temp_html = `<div class="col">
<div class="card h-100">
<img
src=${image}
class="card-img-top"
alt="..."
/>
<div class="card-body">
<h5 class="card-title">${title}</h5>
<p class="card-text">${desc}</p>
<p>${star_image}</p>
<p class="mycomment">${comment}</p>
</div>
</div>
</div>`
$('#cards-box').append(temp_html)
})
});
</script>
</head>
<body>
<div class="mycards">
<div class="row row-cols-1 row-cols-md-4 g-4" id="cards-box">
<div class="col">
<div class="card h-100">
<img
src="https://movie-phinf.pstatic.net/20210728_221/1627440327667GyoYj_JPEG/movie_image.jpg"
class="card-img-top"
alt="..."
/>
<div class="card-body">
<h5 class="card-title">영화 제목이 들어갑니다</h5>
<p class="card-text">여기에 영화에 대한 설명이 들어갑니다.</p>
<p>⭐⭐⭐</p>
<p class="mycomment">나의 한줄 평을 씁니다</p>
</div>
</div>
</div>
</div>
</body>
</html>alt="...” → 대체텍스트
검색엔진에 알고리즘에 영향도 있고 시각장애인들을 위한 음성출력을 위한 텍스트로 쓰여지기 때문에 그들에게는 이미지를 이용하는데에 중요 수단일 수 있어 …보다는 이미지에 설명이 될 수 있는 말을 적는게 좋다.
let star_image = '⭐️'.repeat(star)는 ⭐️이 movie['star']의 값만큼 반복되어 나타난다는 의미이다.
추가로 forEach에 argument로 a를 넣기보다는 movie로 넣어줘야 movies에 각각 하나의 요소라고 이해하기 쉽다.
print(’hi’)
#hi라고 출력이됨.파이썬의 문법은 굉장히 직관적이다.
#숫자, 문자형
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고, ' '를 사용 / " " X
num = 12 # 숫자가 들어갈 수도 있고,
is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다.
#리스트 형 (Javascript의 배열형과 동일)
a=['사과','배','감']
print(a[0]) #사과
#Dictionary 형 (Javascript의 dictionary형과 동일)
a= {}
a= {'name':'영수','age':24}
# a의 값은? {'name':'영수','age':24}
# a['name']의 값은? '영수'
#함수의 정의 - 이름은 마음대로 정할 수 있음!
# 수학문제에서
f(x) = 2*x+3
y = f(2)
y의 값은? 7
# 참고: 자바스크립트에서는
function f(x) {
return 2*x+3
}
# 파이썬에서
def f(x):
return 2*x+3
y = f(2)
y의 값은? 7
-----------------------------
def hey():
print("헤이")
#파이썬에서 함수 생성시, 들여쓰기는 중요해요!
hey() #헤이
def sum(a,b,c):
return a+b+c
result = sum(1,2,3)
print(result) #6#조건문
age = 25
if age > 20:
print("성인입니다")
else:
print("청소년입니다")
#반복문
fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)
#fruits에 하나하나를 fruit로 놓고 반복한다.
# 사과, 배, 감, 귤 하나씩 꺼내어 찍힙니다.
ages =[5,10,13,23,25,9]
for a in ages:
if a>20:
print("성인입니다")
else:
print("청소년입니다")파이썬 패키지 설치하기
서버만들기
- 폴더를 만든다.
- app.py라는 파일을 만든다.
- 터미널을 생성한다.
- 가상환경을 잡는다. (가상환경 : 프로젝트 별로 라이브러리를 담아두는 통)python3 -m venv venv (터미널에 입력)
- 오른쪽 하단에 3.9.6-bit를 눌러서 ‘venv’:venv로 만들어야함 (처음에 생성한 폴더에서 라이브러리를 가져다 쓰는거라고 인식하는거임)
- 새터미널 열어주기
- 새폴더 생성 templates
- templates 에 새파일로 index.html 만들기
- 원하는 프레임워크 깔아주기pymongo dnspython flack bs4
- pip install requests
requests 라이브러리 = feach
<기본뼈대>
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows:
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
print(gu_name,gu_mise)
#rows의 하나하나 요소들을 row라고하고 반복문을 돌린다.
크롤링
웹에 접속해서 데이터를 솎아내어 가지고 오는 것
라이브러리에 접속하는 친구 - requests
솎아내는 친구 - bs4 (BeautifulSoup)
import requests
from bs4 import BeautifulSoup
#requests와 BeautifulSoup을 이용해서
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
#접속 후 데이터를 받아온다.
soup = BeautifulSoup(data.text, 'html.parser')
#받아온 데이터를 솎아낼 준비를해서
print(soup)
#화면에 찍어본다.a = soup.select_one('#old_content > table > tbody > tr:nth-child(3) > td.title > div > a')
print(a.text)
print(a['href'])
#''안에 뭔가를 넣으면 데이터 하나만 솎아낼 수 있다.
# 결과값
#그린 북
#/movie/bi/mi/basic.naver?code=171539
위 이미지처럼 Copy selector 를 통해 가지고 오고싶은걸 찾을 수 있다.
<영화제목들을 다 가져오기>
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
print(a.text)- 크롤링 할 페이지에서 가져올 글에 검사로 tr을 먼저 찾아
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)
이중 공통되는 #old_content > table > tbody > tr 공통되는 걸 변수trs에 넣는다.
(공통되는걸 찾을때는 tr에 우클릭으로 Copy → CopySelector로 가져올 수 있다) - trs를 반복문으로 불러온다.
- tr안에서 내가 가져올
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
공통되는 td.title > div > a를 찾는다. - 찾은 td에 ——— 도 포함이 되어있어 None으로 표시되는데
if a is not None: 을 써서 None이 아닌것만 text로 불러온다.

응용하기 <rank와 star도 동일한 방식으로 가져오기>
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img
#old_content > table > tbody > tr:nth-child(2) > td.point
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text
print(rank, title, star)a는 이미 찾았기때문에 title 변수를 만들어 a.text로 넣어준다.
rank, star도 동일한 방식으로 가져오고 마지막에 원하는 순서로 찍으면 완성
⬇️결과값

아무데서나 크롤링을 할 경우 사이트에 ip를 차단당할 수 있기 때문에 아무데서나 크롤링을 해서는 안된다 ..🥹
<문제>
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?query=날씨')
soup = BeautifulSoup(data.text, 'html.parser')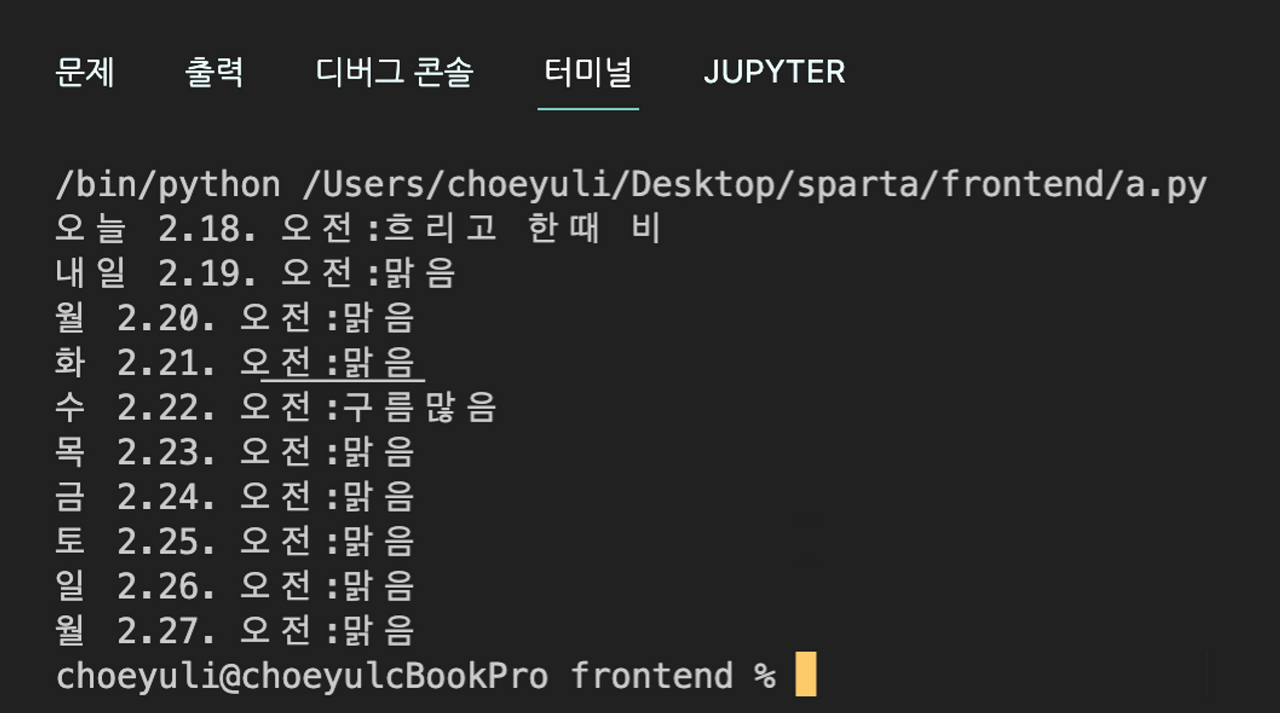
출력해야할 요소는 요일, 날짜, 날씨 입니다.
오전 : ← 직접 입력한 텍스트 입니다.
<정답>
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:test@cluster0.wpply3w.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?query=날씨')
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section.sc_new.cs_weather_new._cs_weather > div._tab_flicking > div.content_wrap > div.content_area > div.inner > div > div.list_box._weekly_weather > ul > li')
for li in lis:
a = li.select_one('div > div.cell_date > span > strong')
if a is not None:
week = a.text
date = li.select_one('div > div.cell_date > span > span').text
morning = '오전:'+li.select_one('div > div.cell_weather > span:nth-child(2) > i > span').text
doc = {'week':week,'date':date,'morning':morning}
db.weeks.insert_one(doc)
print(week, date, morning)mongoDB에 내용이 저장이 되는것까지 완료한 코드이다.
Database

- RDBMS(SQL)
- 행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다.
- 틀이 정해져있어서 대기업 같은 틀이 바뀌지않는 곳에서 유용함.
- ex) MS-SQL, My-SQL 등
- No-SQL
- 딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다.
- 틀을 자주 바꿔야 하는 스타트업 같은곳에서 유용함.
- ex) MongoDB
대부분 No-SQL로 시작해서 틀이 잡히기 시작하면 SQL로 변경해서 사용함.
DB란?
파워포인트, 엑셀과 같이 데이터를 잘 넣어두고 가져다쓰는 프로그램임.
💡요새는 트렌드는 클라우드이다.
mongoDB - Arlas 연결하기
- 패키지 설치하기
mongoDB를 이용하려면 패키지 설치가 필요하다.
pymongo, dnspython- pip install pymongo dnspython 을 입력하고 엔터!
2. pymongo로 조작하기
pymongo 기본코드
from pymongo import MongoClient
client = MongoClient('여기에 URL 입력')
db = client.dbsparta3. mongoDB와 Python 연결하기
mongo atlas 화면에서 Connect를 클릭!

연결 방법 화면에서 Connect your application을 클릭해주세요!

드라이버를 Python으로 버전을 3.6 or later로 클릭하신뒤, 아래에 생성된 링크 버튼을 클릭해 주소를 복사해주세요!

- url 복사 붙여 넣기
- password 부분 수정하기
4. 잘 연결 됐는지 테스트해보기
doc = {
'name':'영수',
'age':24
}
db.users.insert_one(doc)
잘 연결되었다면 mongDB에 들어가게 됨.
pymong사용법. 코드요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})# 모든 데이터 뽑아보기
all_users = list(db.users.find({},{'_id':False}))
print(all_users[0]) # 0번째 결과값을 보기
print(all_users[0]['name']) # 0번째 결과값의 'name'을 보기
for a in all_users: # 반복문을 돌며 모든 결과값을 보기
print(a){'_id':False} → _Id값을 보지 않겠다는 의미
이번 스터디에 내가 준비한 문제가 있었고 그준비과정에서 결국 방법을 찾지 못해서 다른 문제를 냈었는데
근보님은 그 내용을 그대로 가지고 와서 출제 해주셨다. 풀지 못해서 같이 풀어보고자 가저온 모습에 뭔가 더 동기부여가 됬다.
결국 거기서 다시 풀어보려했지만 풀지 못했고 같이 찾아보고 설명을 들어서 이해할 수 있었다.
거기서 추가로 알게된 슬라이스 사용하기는 좀 더 이해하는데 도움이 많이 됬다.
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:test@cluster0.wpply3w.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&mra=bkJB&pkid=3001&qvt=0&query=%EB%84%A4%EC%9D%B4%EB%B2%84%EA%B2%8C%EC%9E%84%EB%9E%AD%ED%82%B9',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
dives = soup.select('#mflick > div > div > div:nth-child(1) > div')
for div in dives:
title = div.select_one('strong > a').text
rank = div.select_one('span > strong').text[2:4]
genre = div.select_one('dl > dd ').text
print(rank,title,genre)
doc= {
'title':title,
'rank': rank,
'genre':genre
}
db.games.insert_one(doc)
<파이썬 슬라이스 사용하기 참고링크>